Handhabung der Genauigkeit von Klassifizierungsmodellen mit unausgewogenen Daten im E-Commerce (Teil-1)
Dec 23, 2023 in Business Intelligenz by Dr. Süleyman Demirci, Sofia Acar
- Einführung
- Was sind unausgewogene Daten?
- Was ist ein Klassifizierungsmodell als ML-Algorithmus?
- Handhabung der Genauigkeit von Klassifizierungsmodellen mit unausgewogenen Daten
- 1. Resampling-Techniken
- 2. Kostensensitives Lernen
- 3. Ensemble-Methoden
- 4. Verwendung alternativer Leistungsmetriken
- Überblick über das Random Forest Modell, SMOTE und SHAP
- Random Forest Modell
- SMOTE
- SHAP
- Kombination von SMOTE und SHAP mit RF
- Bewertung der Leistung des Modells für die Minderheitsklasse
- 1. Vergleich der Ergebnisse von Trainings- und Testdaten
- 2. Kreuzvalidierung
- 3. GridSearchCV und RandomizedSearchCV
- Zusammenfassung
- Die kommende Arbeit
- Referenzen
Einführung
In der sich rasch entwickelnden Landschaft des E-Commerce ist die Nutzung von Daten für die Vorhersagemodellierung von größter Bedeutung. Jedoch ist eine der größten Herausforderungen für Datenwissenschaftler und Analysten der Umgang mit unausgewogenen Daten, insbesondere bei Klassifizierungsmodellen.
Die Analyse und Gewinnung wertvoller Erkenntnisse aus diesen Daten kann nur mit geeigneten Tools und Techniken bewältigt werden. In der Realität sind Daten in der Geschäftswelt selten sauber und bereit für die Analyse. Daten können manchmal folgendes enthalten:
- Extreme Werte
- Nichtstandardisierte Werte (egal ob numerisch oder Text)
- Unausgewogene Werte der abhängigen Variablen
Dies sind schwierige Fragen für einen Datenwissenschaftler oder -analysten, und es dauert lange, solche Daten zu verarbeiten, bevor ein robustes Analysemodell vorliegt.
Es wird vor allem problematischer zu analysieren, wenn unausgewogene Daten vorliegen. Dieses Problem stellt sich insbesondere dann, wenn man mit einemder Klassifizierungsalgorithmen arbeiten möchte. Klassifizierungsmodelle spielen im elektronischen Handel eine entscheidende Rolle, da sie helfen, das Kundenverhalten vorherzusagen und fundierte Entscheidungen zu treffen.
Bei diesen Modellen muss die (abhängige) Ausgangsvariable im Mittelpunkt stehen, um ein Klassifizierungsmodell zu erstellen. Die abhängigen Variablen sind nicht immer gleichmäßig verteilt und in den meisten Fällen wird die Mehrheitsklasse behandelt, während die Minderheitsklasse ignoriert wird. Daher müssen Ingenieure für maschinelles Lernen (ML) die Genauigkeit von Klassifizierungsmodellen mit unausgewogenen Daten sorgfältig prüfen.

Da es den Rahmen eines einzigen Blogs sprengen würde, diese Themen mit praktischen Anwendungen zu behandeln, werden wir zwei weitere Texte veröffentlichen, darunter den aktuellen. Der Rest des Textes wird die vollständigen Leitlinien zur Anwendung dieser Techniken behandeln. Um die Wirksamkeit dieser Techniken zu demonstrieren, haben wir ein Experiment mit einem realen E-Commerce-Datensatz durchgeführt, das im zukünftigen Blogartikel vorgestellt wird.
In diesem Artikel befassen wir uns jedoch nur mit einem umfassenden theoretischen Rahmen für die Random-Forest-Klassifizierungsmodelle und damit, wie die Genauigkeit dieser Modelle zu handhaben ist, da sie sich auf die Minderheitsklasse und nicht auf die Mehrheitsklasse konzentrieren. Daher hilft dieser Artikel E-Commerce-Experten, das volle Potenzial ihrer Daten zu erschließen und ihre Kunden in der sich ständig weiterentwickelnden Welt des Online-Shoppings besser zu bedienen.
Dementsprechend werden wir kurz die Herausforderungen unausgewogener Daten in Klassifizierungsmodellen erörtern und wesentliche Methoden zu deren Handhabung ansprechen. Insbesondere werden wir uns auf Random-Forest-Modelle als eines der Klassifizierungsmodelle konzentrieren und zeigen, wie SMOTE- und SHAP-Techniken die Nachteile unausgewogener Daten in diesem Klassifizierungsmodell verringern können.
Was sind unausgewogene Daten?
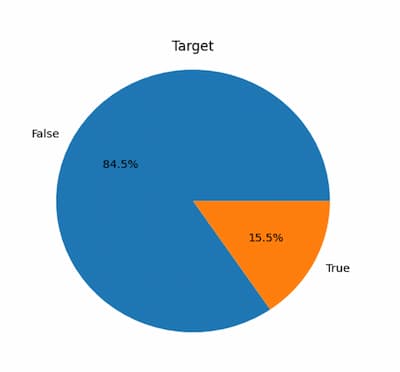
Unausgewogene Daten liegen vor, wenn die Anzahl der Instanzen in einer Klasse signifikant die Anzahl der Instanzen in der anderen Klasse deutlich übersteigt. Im E-Commerce kann dies der Fall sein, wenn die Anzahl der Instanzen in der Klasse „Kaufen“ viel geringer ist als die Anzahl der Instanzen in der Klasse „Nicht Kaufen“. Das Problem bei unausgewogenen Daten ist, dass Klassifizierungsmodell die auf solchen Daten trainiert werden, dazu neigen, die Mehrheitsklasse zu bevorzugen, was zu einer schlechten Leistung in der Minderheitsklasse führt.
Was ist ein Klassifizierungsmodell als ML-Algorithmus?
Ein Klassifizierungsmodell ist eine Methode des maschinellen Lernens, die zur Klassifizierung oder Kategorisierung von Daten in bestimmte Klassen oder Gruppen verwendet wird. Der Hauptzweck eines Klassifizierungsmodells ist die Aufdeckung von Mustern in Daten, die zur Vorhersage der Klassen von neuen, zuvor unbekannten Daten verwendet werden können.
Spam-Filterung, Betrugserkennung, Bilderkennung, Stimmungsanalyse und andere Anwendungen verwenden häufig Klassifizierungsmodelle. Klassifizierungsmodelle werden auch häufig im E-Commerce verwendet, um das Benutzerverhalten vorherzusagen, potenzielle Kunden zu identifizieren und die Unternehmensleistung zu verbessern. Eine Sammlung von Merkmalen oder Eigenschaften stellt die Input-Daten in einem Klassifizierungsmodell dar, und der Output ist eine Kategorienvariable (d.h. die Klassenbezeichnung).
Zu den Klassifizierungsmodellen gehören die logistische Regression, Entscheidungsbäume, Zufallswälder, Support Vector Machines (SVM) und neuronale Netze. Jedes dieser Modelle hat Vor- und Nachteile und ist für verschiedene Arten von Daten und Aktivitäten geeignet.
Um ein Klassifizierungsmodell zu trainieren, ist ein Datensatz mit markierten Beispielen (Daten mit bekannten Klassenbezeichnungen) erforderlich. Danach wird das Modell auf diesen Daten trainiert, um die Muster zu verstehen, die die verschiedenen Klassen identifizieren. Nach dem Training kann das Modell verwendet werden, um die Klassen von neuen, zuvor unbekannten Daten vorherzusagen. Die Leistung eines Klassifizierungsmodells wird häufig anhand von Maßstäben wie Genauigkeit, Präzision, Wiedererkennungswert und F1-Score gemessen, um nur einige zu nennen.
Zur Bewertung eines Klassifizierungsmodells werden diese Scores im Einzelnen definiert:
Genauigkeit: Der Anteil der korrekt klassifizierten Proben an allen Proben. Sie ist eine standardisierte Bewertungskennzahl für ausgewogene Datensätze.
Wiedererkennung: Der Anteil der echten Positiven (korrekt identifizierte Stichprobe der Minderheitenklasse) an allen tatsächlichen Positiven (alle Stichproben der Minderheitenklasse). Es ist eine Metrik, die die Fähigkeit eines Modells misst, alle positiven Proben zu identifizieren.
Präzision: Der Anteil der wahren Positiven unter allen vorhergesagten Positiven. Mit dieser Metrik wird die Fähigkeit eines Modells gemessen, positive Proben korrekt zu identifizieren.
F1-Score: Das harmonische Mittel aus Präzision und Wiedererkennung. Es handelt sich um eine ausgewogene Metrik, die sowohl falsch-positiv als auch falsch-negative Ergebnisse berücksichtigt und üblicherweise für unausgewogene Datensätze verwendet wird.
Gewichteter Durchschnitt: Ein nach der Anzahl der Stichprobe in jeder Klasse gewichteter Durchschnitt aus Präzision, Wiedererkennung und der F1-Punktzahl. Er wird verwendet, um die Gesamtleistung eines Modells auf unausgewogenen Datensätzen zu bewerten.
Makro-Durchschnitt: Ein Durchschnitt aus Präzision, Wiedererkennung und der F1-Punktzahl, der für jede Klasse berechnet und anschließend gemittelt wird. Es gibt das gleiche Gewicht zu jeder Klasse und bewertet die Fähigkeit des Modells, in allen Klassen gut abzuschneiden.
Präzisions-Rückruf-Kurve: Hierbei handelt es sich um eine grafische Darstellung, die den Kompromiss zwischen der Präzision und der Wiedererkennung eines Klassifizierungsmodells bei verschiedenen Wahrscheinlichkeitsschwellenwerten zeigt. Sie ist ein wertvolles Instrument zur Bewertung der Leistung eines binären Klassifizierungsmodells, insbesondere bei unausgewogenen Datensätzen, bei denen die Verteilung der Klassen schief ist.
Handhabung der Genauigkeit von Klassifizierungsmodellen mit unausgewogenen Daten
Eine der größten Herausforderungen für Klassifizierungsmodelle ist der Umgang mit unausgewogenen Daten, bei denen eine Klasse viel mehr Stichproben hat als die andere. Dies kann zu verzerrten Prognosen und schlechter Genauigkeit führen, was sich negativ auf den Erfolg Ihres E-Commerce-Unternehmens auswirken kann. Klassifizierungsmodelle sind leistungsstarke Werkzeuge für E-Commerce-Unternehmen, um Kundendaten zu analysieren und Vorhersagen zu treffen.
Es gibt mehrere Methoden, um die Genauigkeit von Klassifizierungsmodellen mit unausgewogenen Daten im E-Commerce zu verbessern. Lassen Sie uns einige von ihnen diskutieren:
1. Resampling-Techniken
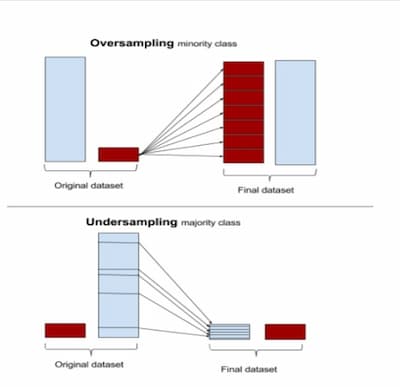
Bei Resampling-Techniken werden die Daten manipuliert, um einen ausgewogenen Datensatz zu erstellen. Die beiden gebräuchlichsten Verfahren sind das Undersampling und das Oversampling. Beim Undersampling werden nach dem Zufallsprinzip einige Instanzen der Mehrheitsklasse entfernt, um den Datensatz auszugleichen. Beim Oversampling werden Kopien der Instanzen der Minderheitsklasse erstellt, um den Datensatz auszugleichen. Das Oversampling kann jedoch zu einer Überanpassung führen, während beim Undersampling wertvolle Daten verloren gehen können.
2. Kostensensitives Lernen
Beim kostensensitiven Lernen werden den verschiedenen Klassen unterschiedliche Fehlklassifikationskosten zugewiesen. Im E-Commerce könnten die Kosten für die Fehlklassifizierung einer „Kaufen“-Instanz als „Nicht Kaufen“ höher sein als die Kosten für die Fehlklassifizierung einer „Nicht Kaufen“-Instanz als „Kaufen“. Durch die Zuweisung unterschiedlicher Fehlklassifizierungskosten kann sich das Modell stärker auf die Minderheitenklasse konzentrieren.
3. Ensemble-Methoden
Bei Ensemble-Methoden werden mehrere Klassifizierungsmodelle kombiniert, um die Leistung zu verbessern. Im E-Commerce können wir mehrere Modelle kombinieren, die jeweils auf einer anderen Teilmenge der Daten oder mit einem anderen Algorithmus trainiert wurden, um ein leistungsfähigeres Modell zu erstellen.
4. Verwendung alternativer Leistungsmetriken
Die Genauigkeit ist nicht immer die beste Leistungskennzahl, um die Leistung eines Klassifizierungsmodells bei unausgewogenen Daten zu bewerten. Stattdessen können wir alternative Leistungsmetriken wie Präzision, Rückruf, F1-Score, Präzisions-Rückruf-Kurve oder AUC-ROC verwenden. Diese Metriken bieten eine detailliertere Bewertung der Leistung des Modells für die Minderheitsklasse.
ML-Ingenieure verwenden diese Methoden und Metriken hauptsächlich, um die Genauigkeit der Mehrheitsklasse von Ausgabevariablen in den Klassifizierungsmodellen zu behandeln. Dieser technische Blog konzentriert sich jedoch darauf, wie man die Genauigkeit der Minderheitsklasse der abhängigen Variablen verbessern kann. In diesem technischen Blog werden drei leistungsstarke Techniken beschrieben, mit denen Sie diese Herausforderung meistern können: Synthetic Minority, Oversampling Technique (SMOTE), SHApley Additive exPlanations (SHAP) und das Random Forest (RF) Modell als Fallstudie. Durch den Einsatz dieser Techniken können Sie die Genauigkeit Ihres Klassifizierungsmodells verbessern und zuverlässigere Ergebnisse erzielen.
Überblick über das Random Forest Modell, SMOTE und SHAP
Random Forest Modell
RF-Modelle sind ein beliebter Algorithmus für maschinelles Lernen, der sich besonders gut für den Umgang mit unausgewogenen Datensätzen eignet. RF-Modelle erstellen eine große Anzahl von Entscheidungsbäumen und kombinieren deren Vorhersagen, um eine endgültige Vorhersage zu treffen. Durch die Verwendung von RF-Modellen können wir die Voreingenommenheit gegenüber der Mehrheitsklasse verringern und die Genauigkeit unseres Klassifizierungsmodells verbessern.
Random Forest ist ein Ensemble-Algorithmus für maschinelles Lernen, der sich sowohl bei Klassifizierungs- als auch bei Regressionsaufgaben großer Beliebtheit erfreut. Er nutzt die Vorteile mehrerer Entscheidungsbäume, um die Genauigkeit und Stabilität der Vorhersagen zu verbessern. Im Vergleich zu anderen Klassifizierungsmodellen weist Random Forest mehrere Vorteile auf, insbesondere im Zusammenhang mit unausgewogenen Datensätzen. So verwendet er beispielsweise ein gewichtetes Abstimmungsschema, um das Problem der unterrepräsentierten Minderheitenklassen in den Trainingsdaten zu lösen. Außerdem kann es hochdimensionale Daten mit korrelierten Merkmalen verwalten, indem es eine Teilmenge von Merkmalen zufällig auswählt.
Ein weiterer großer Vorteil von Random Forest ist, dass er nicht auf ein Ungleichgewicht der Klassen reagiert und sowohl binäre als auch Mehrklassen-Probleme lösen kann. Darüber hinaus zeigt er sich robust gegenüber verrauschten Daten, fehlenden Werten und irrelevanten Merkmalen. Der Algorithmus bietet wertvolle Metriken, wie z.B. Merkmalswichtigkeitsscores, die die Identifizierung der relevantesten Variablen und zugrunde liegenden Muster in den Daten erleichtert.
SMOTE
SMOTE (Synthetic Minority Over-sampling Technique) ist eine häufig verwendete Technik für den Umgang mit unausgewogenen Datensätzen beim maschinellen Lernen. In einem unausgewogenen Datensatz kann eine Klasse deutlich weniger Stichproben haben, als die andere, was zu einer schlechten Leistung von Algorithmen für maschinelles Lernen führt, die auf ausgewogenen Daten beruhen.
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
# create an imbalanced dataset
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3,
n_redundant=1, flip_y=0, n_features=20,
n_clusters_per_class=1, n_samples=1000,
random_state=10)
# apply SMOTE to balance the dataset
m = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
In diesem globalen Beispiel sollten Sie zunächst einen unausgewogenen Datensatz mit der Funktion make_classification() von scikit-learn erstellen. Anschließend wenden Sie den SMOTE-Algorithmus an, um den Datensatz mithilfe der Funktion SMOTE() aus dem Modul imblearn.over_sampling auszugleichen. Der Parameter random_state wird gesetzt, um die Reproduzierbarkeit der Ergebnisse zu gewährleisten. Schließlich erhalten Sie den ausgeglichenen Datensatz, indem Sie die fit_resample()-Methode des SMOTE-Objekts mit den ursprünglichen X und y als Eingaben aufrufen.
Sie sollten feststellen, dass nach der Anwendung von SMOTE die Anzahl der Instanzen in der Minderheitsklasse erhöht wird, um der Anzahl der Instanzen in der Mehrheitsklasse zu entsprechen. Dies kann zu einem insgesamt größeren Datensatz führen. Der ausgewogene Datensatz kann dann für das Training von Klassifizierungsmodellen oder für weitere Analysen verwendet werden.
Die SMOTE-Technik erzeugt daher synthetische Stichproben für die Minderheitsklasse durch Interpolation zwischen vorhandenen Stichproben. Der Algorithmus erzeugt neue Stichproben, indem er Paare aus der Minderheitsklasse auswählt und synthetische Stichproben entlang des Liniensegments, das sie verbindet, erzeugt. Die Anzahl der erzeugten synthetischen Stichproben wird durch einen benutzerdefinierten Parameter bestimmt. Dieser Prozess wird so lange fortgesetzt, bis die Anzahl der Stichproben in der Minderheitsklasse der Anzahl der Stichproben in der Mehrheitsklasse entspricht. Durch die Verwendung von SMOTE können Sie den Datensatz ausgleichen und die Genauigkeit des Klassifizierungsmodells verbessern.
Der Hauptvorteil von SMOTE besteht darin, dass es dazu beiträgt, den Datensatz ohne zusätzliche Datenerfassung auszugleichen. Dies kann besonders nützlich sein, wenn die Erhebung zusätzlicher Daten teuer oder unpraktisch ist. Darüber hinaus hat sich gezeigt, dass SMOTE die Leistung von Modellen für maschinelles Lernen bei unausgewogenen Datensätzen verbessert, was es zu einer beliebten Wahl für Datenwissenschaftler und Praktiker des maschinellen Lernens macht.
Es ist jedoch unbedingt zu beachten, dass SMOTE keine Universallösung für unausgewogene Datensätze ist und seine Wirksamkeit von den spezifischen Merkmalen des Datensatzes und dem verwendeten Algorithmus für maschinelles Lernen abhängen kann. Es wird immer empfohlen, mit mehreren Techniken zu experimentieren und ihre Leistung mit dem gewünschten Datensatz zu vergleichen, bevor man sich für den besten Ansatz entscheidet.
SHAP
SHAP (Shapley Additive exPlanations) ist eine modellunabhängige Methode, die individuelle Vorhersagen in Modellen des maschinellen Lernens erklärt, einschließlich solcher, die für unausgewogene Datensätze verwendet werden. Sie basiert auf dem Konzept der Shapley-Werte aus der Spieltheorie, einer Methode zur Zuweisung eines fairen Anteils an der Gesamtbelohnung eines kooperativen Spiels an jeden Spieler. Im Kontext des maschinellen Lernens weist SHAP jedem Merkmal für eine bestimmte Vorhersage einen Wichtigkeitswert zu, der angibt, wie viel jedes Merkmal zum Endergebnis beiträgt.
Bei unausgewogenen Datensätzen kann SHAP verwendet werden, um zu verstehen, welche Merkmale für die Mehrheitsklasse und die Minderheitsklasse am wichtigsten sind. Dies kann dazu beitragen, mögliche Verzerrungen im Modell zu erkennen und sicherzustellen, dass das Modell nicht nur für die Mehrheitsklasse optimiert wird. Darüber hinaus kann SHAP helfen zu erklären, warum bestimmte Vorhersagen gemacht wurden, und gibt so Einblick in den Entscheidungsprozess des Modells.
Um SHAP zu verwenden, muss zunächst ein maschinelles Lernmodell für den ausgewogenen Datensatz trainiert werden. Sobald das Modell trainiert ist, kann SHAP verwendet werden, um den Wichtigkeitswert jedes Merkmals für eine bestimmte Vorhersage zu berechnen. Durch die Identifizierung der wichtigsten Merkmale sowohl für die Mehrheits- als auch für die Minderheitsklasse kann SHAP sicherstellen, dass das Modell nicht verzerrt ist und das Verhalten aller Kundensegmente genau erfasst.
Hier ist ein allgemeines Beispiel für Python-Code:
import shap
from sklearn.ensemble import RandomForestClassifier
# load the dataset
ata = pd.read_csv(“online_shoppers_intention.csv”)
X, y = data.drop(data.target, axis=1), data[‘target’]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# train a Random Forest classifier
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)
# initialize the SHAP explainer
explainer = shap.TreeExplainer(clf)
# calculate the SHAP values for the testing set
shap_values = explainer.shap_values(X_test)
# plot the SHAP summary plot for the first feature
shap.summary_plot(shap_values[0], X_test, feature_names=data.feature_names)
In diesem Code sehen Sie, dass Sie zunächst den Datensatz laden und ihn in Trainings- und Testsätze aufteilen. Dann trainieren Sie einen Random-Forest-Klassifikator auf dem Trainingssatz und initialisieren einen SHA-Erklärer unter Verwendung des trainierten Modells. Anschließend sollten Sie die SHAP-Werte für den Testdatensatz mit der Funktion shap_values() berechnen und eine zusammenfassende Darstellung mit der Funktion summary_plot() erstellen.
Sie sollten beachten, dass die SHAP-Werte für jedes Merkmal im Datensatz berechnet werden, so dass das shap_values-Objekt ein zweidimensionales Array ist. Sie können die SHAP-Werte für jedes Merkmal mit der Funktion summary_plot() darstellen, die den Einfluss jedes Merkmals auf die Ausgabe des Modells zeigt. Das Argument feature_names wird verwendet, um die Merkmale in der Darstellung zu benennen.
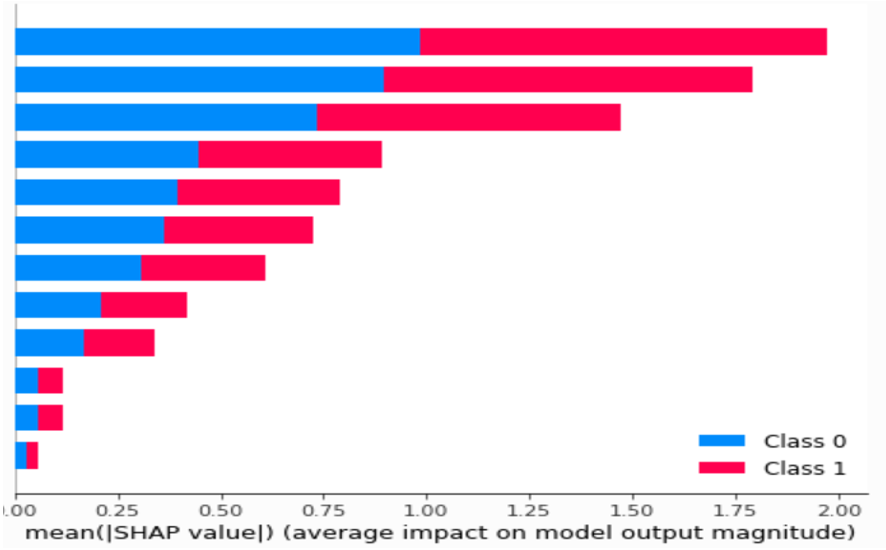
SHAP wäre die richtige Wahl, um zu erklären, warum das RF-Modell eine bestimmte Vorhersage trifft. Diese Technik ist daher hilfreich, um zu bestimmen, welche Merkmale im Datensatz für die Vorhersage des Kundenverhaltens wesentlich sind, und um zu verstehen, wie das Modell seine Vorhersage im Zusammenhang mit dem E-Commerce trifft. SHAP könnte verwendet werden, um festzustellen, welche Produktmerkmale für die Vorhersage, ob ein Kunde das Produkt kaufen wird, am wichtigsten sind. Die Kenntnis des wichtigsten Prädiktors für die Vorhersage des Kundenverhaltens kann auch helfen, des E-Commerce-Marketing zu verbessern.
Kombination von SMOTE und SHAP mit RF
Die Kombination von SMOTE und SHAP mit RF-Modellen kann die Klassifizierungsleistung bei unausgewogenen Daten verbessern und Erkenntnisse über die Bedeutung von Merkmalen für die Vorhersage des Kundenverhaltens liefern.
Um SMOTE und RF zu kombinieren, verwenden wir zunächst SMOTE, um den Datensatz auszugleichen, indem wir synthetische Instanzen der Minderheitenklasse erzeugen. Dann trainieren wir ein RF-Modell auf dem ausgewogenen Datensatz. Schließlich verwenden wir SHAP, um die Ausgabe des RF-Modells zu erklären und die wichtigen Merkmale zu identifizieren.
Die Verwendung von SMOTE und SHAP mit RF-Modellen kann rechenintensiv sein, insbesondere bei großen Datensätzen. Die mit diesen Techniken gewonnenen Erkenntnisse können jedoch wertvolle Informationen für fundierte Entscheidungen im E-Commerce liefern.
Bewertung der Leistung des Modells für die Minderheitsklasse
Die Bewertung der Leistung des maschinellen Lernens ist von entscheidender Bedeutung, um ihre Wirksamkeit und Zuverlässigkeit zu bestimmen. Dies ist besonders bei unausgewogenen Datensätzen wichtig, bei denen der Anteil der Stichproben, die zu jeder Klasse gehören, ungleich ist und Modelle leicht zur Mehrheitsklasse tendieren können.
Im nächsten Teil der Serie werden wir einen unausgewogenen Datensatz verwenden; daher werden verschiedene Bewertungsmetriken, einschließlich Präzision, Wiedererkennung und F1-Score, verwendet, um die Leistung der Modelle zu bewerten. Diese Metriken werden beim maschinellen Lernen häufig verwendet, um die Qualität von binären Klassifizierungsmodellen zu bewerten und einen Einblick in die Fähigkeit des Modells zu geben, positive und negative Proben korrekt zu identifizieren.
Zusätzlich zu diesen Metriken werden wir auch den Makro-Durchschnitt verwenden, eine wichtige Metrik für unausgewogene Datensätze. Der Makro-Durchschnitt berücksichtigt die Leistung des Modells sowohl in den Mehrheits- als auch in den Minderheitsklassen und bietet einen ausgewogeneren Überblick über die Gesamtleistung des Modells.
Um die Leistung der Modelle weiter zu bewerten, müssen wir die Präzisions-Recall-Kurven aufzeichnen und die entsprechenden Werte bewerten, die nützliche Kriterien für unausgewogene Datensätze sind. Diese Metrik bietet eine grafische Darstellung des Kompromisses zwischen Präzision und Recall und kann dabei helfen, den am besten geeigneten Schwellenwert für die Klassifizierung zu bestimmen.
Nach der Modellierung müssen mehrere Faktoren berücksichtigt werden, um die Zuverlässigkeit der erzielten Ergebnisse zu gewährleisten.
1. Vergleich der Ergebnisse von Trainings- und Testdaten
Der Unterschied zwischen Trainings- und Testdaten ist folgender: Trainingsdaten werden verwendet, um das Modell zu trainieren, während Testdaten verwendet werden, um die Leistung des Modells bei zuvor nicht gesehenen Daten zu überprüfen.
Wenn Sie gute Ergebnisse in der Trainingsgruppe, aber schlechte Ergebnisse in der Testgruppe erzielen, liegt wahrscheinlich ein Overfitting-Problem vor. Overfitting tritt in Situationen mit geringer Verzerrung und hoher Varianz auf. Dies bedeutet, dass sich das Modell übermäßig an die Trainingsdaten angepasst hat und sich die Informationen effektiv gemerkt hat, anstatt sie zu lernen.
Um Overfitting in den Griff zu bekommen, sollten Sie folgende Techniken anwenden:
- Vergrößerung der Trainingsdaten
- Reduzierung der Modellkomplexität
- Regularisierung
Wenn Sie hingegen sowohl bei den Trainings- als auch bei den Testdaten niedrige Werte erzielen, liegt wahrscheinlich ein Underfitting-Problem vor. Underfitting tritt in Situationen mit hoher Verzerrung und geringer Varianz auf, was bedeutet, dass sich das Modell nicht ausreichend an die Trainingsdaten anpassen kann, was zu einer Verallgemeinerung führt.
Um das Problem des Underfitting in den Griff zu bekommen, sollten Sie folgende Techniken anwenden:
- Erhöhung der Modellkomplexität
- Entfernung von Rauschen aus den Daten
- Erhöhung der Trainingszeit
- Ensemble-Methoden
2. Kreuzvalidierung
Die Kreuzvalidierung ist eine Technik zur Bewertung der Generalisierungsfähigkeit eines Modells. Bei diesem Verfahren wird der Datensatz in verschiedene Teilmengen (folds) unterteilt und das Modell nacheinander an jeder Teilmenge getestet. Auf diese Weise lässt sich messen, wie gut sich das Modell an neue, noch nicht gesehene Daten anpassen kann.
Hier ist ein allgemeines Beispiel für die Kreuzvalidierung:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
data = pd.read_csv(“online_shoppers_intention.csv”)
X, y = data.drop(data.target, axis=1), data[‘target’]
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier(random_state=42))
])
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print("Cross-validation scores: ", cv_scores)
print("Mean CV score: ", np.mean(cv_scores))
Im obigen Beispiel wird die Pipeline, die mit dem Standard-Skalierer und dem Random-Forest-Modell erstellt wurde, mit einer 5-fachen Kreuzvalidierung bewertet und die Kreuzvalidierungsergebnisse werden berechnet.
3. GridSearchCV und RandomizedSearchCV
Die Auswahl optimaler Parameter spielt eine entscheidende Rolle bei der Verbesserung der Modellleistung und der Bestimmung der besten Parameter für ein bestimmtes Modell. Scikit-learn bietet zu diesem Zweck zwei allgemeine Ansätze: GridSearchV, bei dem alle Parameterkombinationen für die angegebenen Werte erschöpfend betrachtet werden, und RandomizedSearchCV, bei dem eine feste Anzahl von Kandidaten aus einem Parameterraum mit einer definierten Verteilung ausgewählt wird.
RandomizedSearchCV führt eine zufällige Suche über die Parameter durch, wobei jede Einstellung aus einer Verteilung möglicher Parameterwerte entnommen wird. Diese Methode hat zwei Hauptvorteile gegenüber einer umfassenden Suche:
- Ein Budget kann unabhängig von der Anzahl der Parameter und deren möglichen Werten festgelegt werden.
- Das Hinzufügen von Parametern, die keine Auswirkungen auf die Leistung haben, beeinträchtigt die Effizienz nicht.
Ein Wörterbuch wird verwendet, um anzugeben, wie die Parameter instanziiert werden sollen, ähnlich wie bei GridSearchCV. Darüber hinaus wird ein Berechnungsbudget definiert, das der Anzahl der Kandidaten oder Stichprobeniterationen entspricht, die durch den Parameter n_iter angegeben werden.
Hier ist ein allgemeines Beispiel für RandomizedSearchCV:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
data = pd.read_csv(“online_shoppers_intention.csv”)
X, y = data.drop(data.target, axis=1), data[‘target’]
rf_classifier = RandomForestClassifier(random_state=42)
param_dist = {
'n_estimators': randint(10, 200),
'max_depth': randint(1, 10),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 10),
}
random_search = RandomizedSearchCV(rf_classifier,
param_distributions=param_dist,
n_iter=50, cv=5, random_state=42)
random_search.fit(X, y)
print("Best parameters: ", random_search.best_params_)
print("Best score: ", random_search.best_score_)
Zusammenfassung
Schlussendlich ist der Umgang mit unausgewogenen Daten in E-Commerce-Klassifizierungsmodellen äußerst wichtig, um genaue und verlässliche Vorhersagen zu treffen. Dies ist im E-Commerce von großer Bedeutung, da das Verständnis des Kundenverhaltens und seiner Vorlieben zu besseren Marketingstrategien zu mehr Umsatz führen kann. Mithilfe von Techniken wie Resampling, kostensensitivem Lernen, Ensemble-Methoden und verschiedenen Leistungsmetriken können wir unsere Klassifizierungsmodelle mit unausgewogenen Daten besser funktionieren lassen und in realen Situationen hilfreich sein.
Es ist wichtig, sich auf die Zuverlässigkeit der Ergebnisse der Minderheitsklasse zu konzentrieren, insbesondere bei der Arbeit mit unausgewogenen Daten. Techniken wie SMOTE und SHAP können hilfreich sein, aber sie haben möglicherweise einige Einschränkungen, so dasswir bei ihrer Verwendung vorsichtig sein sollten. Wir sollten die Modelle immer feinabstimmen, um sicherzustellen, dass sie zuverlässig bleiben und mit der sich ständig verändernden Welt des elektronischen Handelns Schritt halten.
Vergessen Sie auch nicht die Kreuzvalidierung und die Optimierung der Hyperparameter, wie GridSearchCV und RandomizedSearchCV. Diese Techniken helfen unseren Modellen, besser mit neuen unbekannten Daten umzugehen und ihre Gesamtleistung zu verbessern. Durch gründliches Testen und Verbessern unserer Modelle können wir starke Klassifizierungsmodelle erstellen, die uns wertvolle Einblicke in das Kundenverhalten geben und uns helfen, bessere Entscheidungen auf der Grundlage von Daten zu treffen.
Kurz gesagt: Das Geheimnis des Erfolgs bei der E-Commerce-Klassifizierung besteht darin, die Besonderheiten unausgewogener Daten zu kennen und die richtigen Techniken anzuwenden, um sicherzustellen, dass unsere Vorhersagen genau und zuverlässig sind. Durch ständiges Experimentieren und Lernen können E-Commerce-Experten Klassifizierungsmodelle erstellen und pflegen, die zu Wachstum und Erfolg in der wettbewerbsorientierten E-Commerce-Branche führen.
Die kommende Arbeit
Im nächsten Teil dieser Serie werden wir uns mit dem Problem des Klassenungleichgewichts in einem E-Commerce-Datensatz unter Verwendung verschiedener ML-Algorithmen, SMOTE- und SHAP-Techniken befassen. So wird der folgende Text zu einem umfassenden Leitfaden für die Behandlung von Genauigkeitsproblemen bei unausgewogenen Daten. Diese Reihe ist ein wichtiger Schritt zum Verständnis des Kundenverhaltens in der E-Commerce-Branche und wird dazu beitragen, bessere Marketingstrategien zu entwickeln.
Referenzen
https://blog.hubspot.com/service/customer-segmentation?hubs_content=blog.hubspot.com%2Fservice%2Fcustomer-segmentation&hubs_content-cta=What%20is%20customer%20segmentation%3F
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357
https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
https://proceedings.neurips.cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf
https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-10-13
https://machinelearningmastery.com/bagging-and-random-forest-for-imbalanced-classification/
Chen, Y., Li, H., Liu, S., Liu, J., & Chen, H. (2021). Random Forest for Imbalanced
https://towardsdatascience.com/shap-explain-any-machine-learning-model-in-python-24207127cad7
https://scikit-learn.org/stable/modules/model_evaluation.html
https://en.wikipedia.org/wiki/Overfitting
https://www.geeksforgeeks.org/underfitting-and-overfitting-in-machine-learning/
https://towardsdatascience.com/overfitting-and-underfitting-principles-ea8964d9c45c
https://scikit-learn.org/stable/modules/cross_validation.html
https://scikit-learn.org/stable/modules/grid_search.html#grid-search